

此内容包含简单的基础知识准备,以及爬虫,仅为个人笔记
基础知识
type()
判断括号中的变量类型
%s,%d,%c
在字符串中分别表示字符串类型,int类型和char类型,如下例子
1 | a="hello" |
两者结果一致
字符中多次出现可以用
1 | for i in range(0,9): |
位运算符
假设a=60,b=13
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 与运算符:参与运算的两个值,如果相应位都为1,则该位的结果为1,否则为0 | (a&b)输出结果为12,二进制解释为00001100 |
| | | 或运算符:只要对应两个二进制有一个为1时,结果就为1 | (a|b)结果为61,二进制解释为00111101 |
| ^ | 异或运算符:当对应的两个二进制位相异时,结果为1 | (a^b)结果为49,二进制解释为00110001 |
| ~ | 取反运算符:对数据的每个二进制位取反,即把1变成0,0变成1.~x类似与-x-1 | (~a)结果为-61,二进制解释为11000011,在一个有符号二进制数的补码形式 |
| << | 左移动运算符:运算数的二进位全部左移若干位,由”<<”右边数字指定移动位数,高位丢弃,低位补0。 | a<<2输出结果240,二进制解释为11110000 |
| >> | 右移动运算符:同上 | a>>2结果为15,二进制解释为00001111 |
进制转换
比如将二进制数0b111100转为十进制,则命令为
int('0b111100',2)参考int(‘number’,base=number)
正则表达式
这里给出一个非常棒的博客链接,写的非常详细
| 操作符 | 说明 | 实例 |
|---|---|---|
| . | 表示任何单个字符 | |
| [ ] | 字符集对单个字符给出取值范围 | [abc]表示a, b, c, [a-z]表示a到z单个字符 |
| [^ ] | 非字符集,对单个字符给出排除范围 | [^abc]表示非a或b或c的单个字符 |
| * | 前一个字符0次或无限次扩展 | abc*表示ab, abc, abcc, abccc等等 |
| + | 前一个字符1次或无限次扩展 | abc+表示abc, abcc, abccc等等 |
| ? | 前一个字符0次或1次扩展 | abc?表示ab, abc |
| | | 左右表达式任意一个 | abc|def 表示 abc、def |
| {m} | 扩展前一个字符m次 | ab{2}c表示abbc |
| {m,n} | 扩展前一个字符m至n次(含n) | ab{1,2}c表示abc、abbc |
| ^ | 匹配字符串开头 | ^abc表示abc且在一个字符串的开头 |
| $ | 匹配字符串结尾 | abc$表示abc且在一个字符串的结尾 |
| ( ) | 分组标记,内部只能使用 | 操作符 | (abc)表示abc,(abc|def)表示abc、def |
| \d | 数字,等价于[0-9] | |
| \w | 单词字符,等价于[A-Za-z0-9_] | 只能包含,数字0-9,大小写字母a-z,A-Z以及下划线 |
\w的要求所以很多用户名密码不允许出现汉字和其他字符但允许下划线
在python中的re库里的功能有
| 函数 | 说明 |
|---|---|
| re.search() | 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 |
| re.match() | 从一个字符串的开始位置起匹配正则表达式,返回match对象 |
| re.findall() | 搜索字符串,以列表类型范围全部能匹配的子串 |
| re.split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
| re.finditer() | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象 |
| re.sub() | 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 |
正则表达式可以包含一些可选标志修饰符来控制匹配模式。修饰符被指定为一个可选的标志。多个标志可以按位OR(|)来指定。如re.l | re,M 被设置成 I 和 M标志:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响^和$ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符解析字符。这个标志影响\w, \W, \b, \B |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写的更易于理解。 |
给出几个例子
search()
1 | import re |
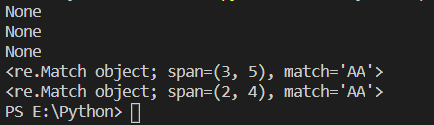
运行结果如上,无结果返回None,有结果返回对应位置,前闭后开,且只会匹配第一个出现的
也可以简写m=re.search("AA",item)(前面为正则匹配规则,后面为查找内容)
findall()
再如,找出字符串中的所有大写字母
re.findall("[A-Z]","ajsSAsdfjlaEifSAKLvioawhS): 结果[‘S’, ‘A’, ‘E’, ‘S’, ‘A’, ‘K’, ‘L’, ‘S’]
re.findall("[A-Z]+","ajsSAsdfjlaEifSAKLvioawhS): 结果[‘SA’, ‘E’, ‘SAKL’, ‘S’]
输出结果会将字符串中的所有大写字母单个摘出组成列表返回
sub()
re,sub("a","A","jfdasjASfowihegdFJwqEJFsdfoahewhfHEH"): 找到a,使用A替换
所以print(re.sub("[a-z]{2,5}","A","jfdasjASfowihegdFJwqEJFsdfoahewhfHEH"))意思为连续二到五个小写字母会被替换为A。因此结果为AjASAAFJAEJFAAHEH
建议在正则表达式中被比较的字符串前加上r,因此不用担心转义字符的问题
保存数据(xlwt使用)
1 | import xlwt |
爬虫部分
Get方式发送请求
1 | import urllib.request |
Post方式发送请求
1 | import urllib.request |
超时处理
在真实爬虫过程中,为防止各种情况出现的请求超时(如被拦截,发现等等),需要做好准备,可用try···except进行过滤
1 | import urllib.request |
其中可用print(response.status)来查看相应的状态码,注意418状态码意味着对方发现你是一个爬虫*
响应头可用print(response.getheader())来得到,括号中可添加具体想得到的内容名儿
请求头伪装
伪装正常浏览器的参数达到爬取的目的
1 | import urllib.request |
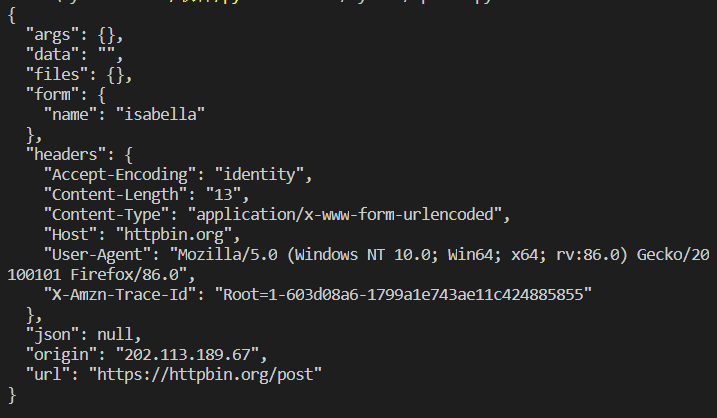
正确返回的结果如上
数据解析
beautifulsoup的使用
将html分成四个可用节点
- Tag: 标签
- NavigableString: 标签里的字符串内容
- BeautifulSoup: 分析好的类
- Comment
1 | from bs4 import BeautifulSoup |
注意,只能读取第一个标签以及内容
bs.title.string可以省略<title>,而只打印内容也即“百度一下,你就知道”
文档的遍历
print(bs.head.contents)可以打印读取html的头部的内容
print(bs.head.contents[1])因为返回的内容是一个列表,所以用[1]来特定读取
文档的搜索
- find_all
t_list=bs.find_all("a"): 找到所有a标签,并返回一个列表
- 正则表达式搜索
search()方法来进行比配内容
t_list=bs.find_all(re.compile("a")): 需要引入re库,使用正则匹配找到的所有内容中含有a字符的内容(如head也含有a字符)
t_list=bs.find_all(re.compile("\d")): 应用正则表达式将所有数字内容(标签里的自字符串)找出来
- 根据函数的要求来搜索
1 | def name_is_exists(tag): |
- 参数搜索
t_list=bs.find_all(class_=True): 找出所有带class属性及其子内容注意class后面接一个下划线_
t_list=bs.find_all(href="http://news.baidu.com"): 同上,链接参数
t_list=bs.find_all(text="hao123"): 查找特定内容,可以传入列表,即text=[“1”,”2”,”3”]
t_list=bs.find_all("a",limit=3): 限定查找多少个
- CSS选择器查找
t_list=bs.select("title"): 通过标签筛选
t_list=bs.select(".mnav"): 通过类名筛选
t_list=bs.select("#u1"): 通过ID筛选
还可以
t_list=bs.select("a[class='bri']"): 来筛选特定a属性中的特定class类
t_list=bs.select(".mnav ~ .bri"): mnav标签中的bri子标签内容print(t_list[0].get_text())得到文本,第一个元素的文本内容
爬虫实例
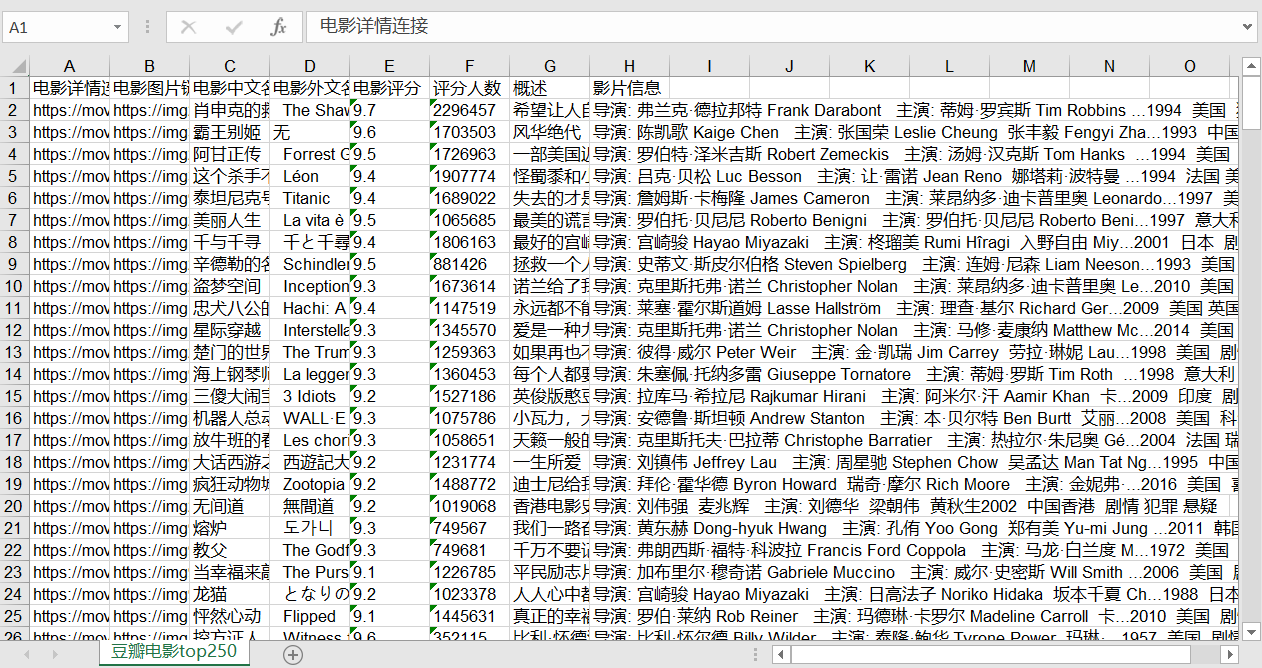
1 | from bs4 import BeautifulSoup |
实际保存效果
[toc]


- 本文作者: Isabella
- 本文链接: https://username.github.io/2021/03/02/python爬虫/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!
 Myself
Myself